NVIDIA 正式发布全新「GeForce RTX 3080」绘图卡,採用全新「GA-102-200」绘图核心,升级新一代 Ampere GPU 微架构、增至 8,704 个 CUDA Cores、第 2 代 RT Cores 及第 3 代 Tesnsor Cores 与10GB GDDR6X 记忆体,更换上创新的轴向式双风扇散热器,性能是 GeForce RTX 2080 的两倍,官方定价 US$699、开 4K 光追顺畅玩游戏不再是梦。
GeForce RTX 30 系列登场

GeForce RTX 30 系列 (3070 / 3080 / 3090)
NVIDIA 17 日正式发布首款「Ampere」GPU 微架构产品、核心代号为「GA102」的效能级「GeForce RTX 3080」,号称是 NVIDIA GPU 史上最大的架构跃进,採用 NVIDIA 的第二代 RTX 架构 Ampere,配备更快速的第二代光线追蹤核心、更快速的第三代 Tensor 核心、全新 Ampere SM 串流多处理器及 GDDR6X 记忆体。
整个 NVIDIA Ampere 架构都是为提高效率而设计的,从定制流程设计到电路设计,逻辑设计,封装,内存,电源和散热设计,再到 PCB 设计以及软件和算法,为 PC 游戏带来全新的领域。

除了 GeForce RTX 3080 新卡,NVIDIA 将会在 9 月 24 日再发布旗舰级 GeForce RTX 3090,同样基于 GA102 绘图核心,高达 10,496 CUDA Cores、24GB GDDR6X,启用 DLSS 8K 模式后,可以在大部份游戏中以 8K @ 60Hz 执行游戏,售价为 US$1,499。
10 月 15 日将会再推出效能级 GeForce RTX 3070,採用 GA104 绘图核心、内建 5,888 CUDA Cores、8GB GDDR6,提供可与 NVIDIA 上一代旗舰 GeForce RTX 2080 Ti 媲美的性能,售价仅 US$499,你叫买了 RTX 2080 Ti 的玩家情何以堪呢。
SAMSUNG 8nm 制程、 NVIDIA GA102 绘图核心
NVIDIA GA102 绘图核心基于全新 Ampere GPU 微架构,并用于 GeForce RTX 3080 与 GeForce RTX 3090 产品之中,性能的提升主要来自 FP32 运算单元提升了 1 倍、升级第 2 代 RT Cores、升级第 3 代 Tensor Cores,经改良的 ROP 单元及换上更高速的 GDDR6X 记忆体,与上代 Turing GPU 微架构比较,传统光栅图形运算提高了 1.7 倍,同时在光线追踪性能上提升近 2 倍。
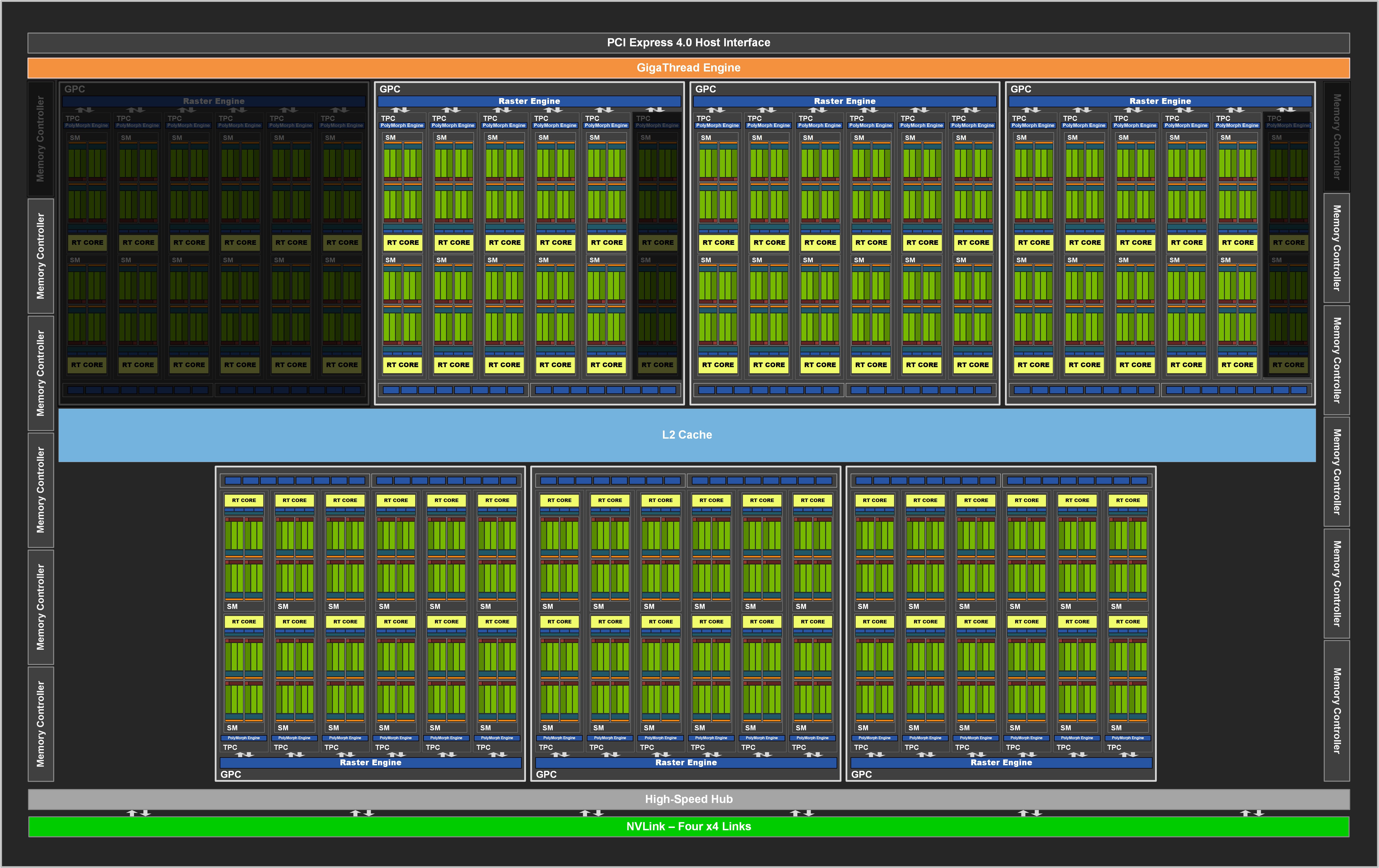
NVIDIA GA102-200 Block Diagram
「GeForce RTX 3080」採用「GA102-200」绘图核心,採用 8nm NVIDIA Custom 制程、SAMSUNG 代工,拥有 283 亿个电晶体、Die Size 约为 628mm²,完整的 GA102 晶片内建 7 个 GPC 单元、42 个 TPC 纹理处理群集及 84 个 SM 串流多处理器,增至 10,752 个 CUDA Cores、84 个 RT Cores 及 336 个 Tensor Cores。

NVIDIA GA102-200-KA-A1 绘图核心
不过,「GeForce RTX 3080」部份单元作出了屏蔽,删减至只有 6 个 GPC 单、34 个 TPC 纹理处理群集及 68 个 SM 串流多处理器,具备 8,702 个 CUDA Cores、68 个 RT Cores 及 272 个 Tensor Cores。
核心时脉方面,虽然晶片规模大幅提升但时脉仍能保持于高水平,GeForce RTX 3080 预设时脉为 1,440MHz Base Clock、1,710 MHz Boost Clock,最高 TDP 为 320W。此外,「GeForce RTX 3080」改用了全新 GDDR6X 记忆体颗粒,虽然记忆体时脉只有1,188MHz,传输速度却高达 19Gbps,加上 320 bit 记忆体频宽介面,令总频宽 提升 760GB/s。
Graphics Card
GeForce RTX 2080
Founders Edition
GeForce RTX 2080 Super
Founders Edition
GeForce RTX 3080 10 GB
Founders Edition
GPU Codename
TU104
TU104
GA102
GPU Architecture
NVIDIA Turing
NVIDIA Turing
NVIDIA Ampere
GPCs
6
6
6
TPCs
23
24
34
SMs
46
48
68
CUDA Cores / SM
64
64
128
CUDA Cores / GPU
2944
3072
8704
Tensor Cores / SM
8 (2nd Gen)
8 (2nd Gen)
4 (3rd Gen)
Tensor Cores / GPU
368
384 (2nd Gen)
272 (3rd Gen)
RT Cores
46 (1st Gen)
48 (1st Gen)
68 (2nd Gen)
GPU Boost Clock (MHz)
1800
1815
1710
Peak FP32 TFLOPS (non-Tensor)1
10.6
11.2
29.8
Peak FP16 TFLOPS (non-Tensor)1
21.2
22.3
29.8
Peak BF16 TFLOPS (non-Tensor)1
NA
NA
29.8
Peak INT32 TOPS (non-Tensor)1,3
10.6
11.2
14.9
Peak FP16 Tensor TFLOPS
with FP16 Accumulate1
84.8
89.2
119/2382
Peak FP16 Tensor TFLOPS with FP32 Accumulate1
42.4
44.6
59.5/1192
Peak BF16 Tensor TFLOPS
with FP32 Accumulate1
NA
NA
59.5/1192
Peak TF32 Tensor TFLOPS1
NA
NA
29.8/59.52
Peak INT8 Tensor TOPS1
169.6
178.4
238/4762
Peak INT4 Tensor TOPS1
339.1
356.8
476/9522
Frame Buffer Memory Size and Type
8192 MB GDDR6
8192 MB GDDR6
10240 MB GDDR6X
Memory Interface
256-bit
256-bit
320-bit
Memory Clock (Data Rate)
14 Gbps
15.5 Gbps
19 Gbps
Memory Bandwidth
448 GB/sec
496 GB/sec
760 GB/sec
ROPs
64
64
96
Pixel Fill-rate (Gigapixels/sec)
115.2
116.2
164.2
Texture Units
184
192
272
Texel Fill-rate (Gigatexels/sec)
331.2
348.5
465
L1 Data Cache/SharedMemory
4416 KB
4608 KB
8704 KB